这篇文章将向大家介绍机器人抓取物体方面的一篇论文GraspNet-1Billion[1]和其开源代码[2]的实现思路,GraspNet仅面向单臂机器人抓取物体任务,和RT-1,RT-2较为通用的任务相比有一些不同,他们的对比具体可以参考[3]:
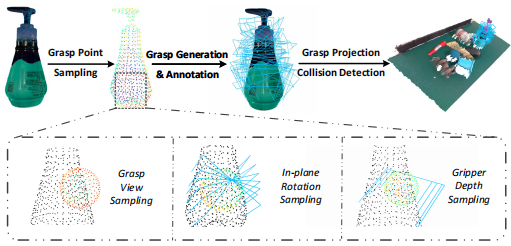
数据集构建:数据收集和标注的方法可以参考[4],其中从DexNet2.0中收集的13种对抗性物体(adversarial objects),对抗性的含义是指表面较为复杂难以标注。由于抓取姿势和传统的视觉标注任务(如目标检测语义分割)等不同,抓取姿势分布在大的连续搜索空间(如图1所示),因此采用了力学(force-closure metric)等物理模型通过在离散化的搜索空间(其中平面一般基于抓取点的附近点云拟合抓取点的切平面的思路去确定,将搜索空间通过两个维度上的离散化即in-plane rotation sampling和depth sampling对抓取pose的搜索空间进行离散化采样),对每种抓取姿势进行评分。为了使得采样姿势多样,在采集数据时,只需要标注第一帧,后续的视频轨迹可以根据记录下来的位姿变换对抓举姿势进行传播计算。
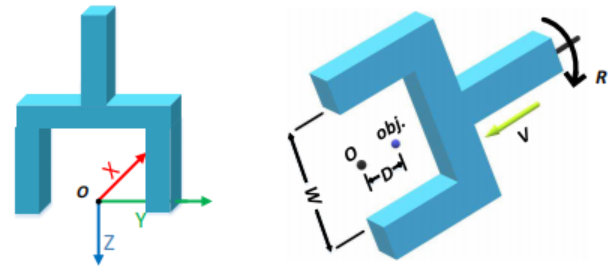
关于夹爪坐标系有两点需要说明:(1)、平行夹爪的原点一般定义为其两个平面内面最下端的中间点,(2)、z轴指向夹爪当前的朝向(夹持物体的方向)。因为在模型生成时,一般在对应物体的表面的采样选择候选抓取点,在机器人RGB-D点云输入网络模型生成抓取位姿后,机械臂需要通过路径规划和轨迹生成实现从当前位置到目标位置的平滑运动。这里的抓取姿势采用7自由度(7-DoF)表示法。如图2所示,网络会预测如下几个部分的量(夹爪pose):(1)approaching vector v,亦即为物体目标点到夹爪原点形成的方向向量;(2) d为目标点和夹爪原点的距离;(3),R为夹爪转轴的旋转状态。
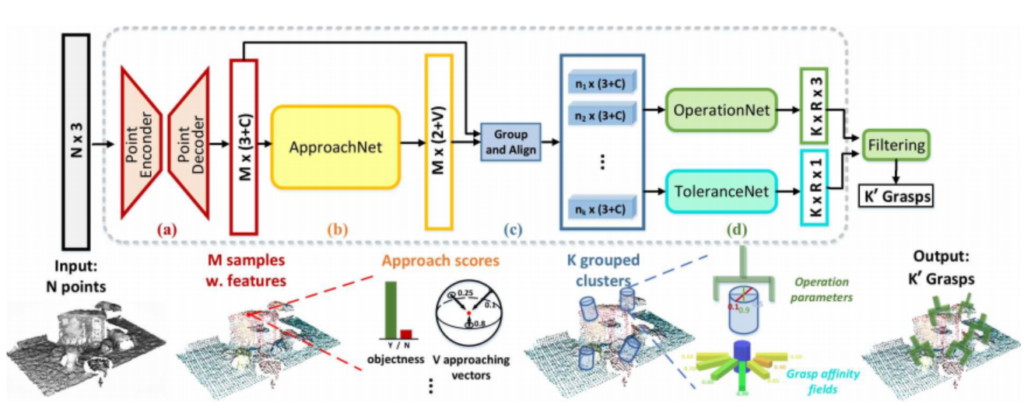
模型结构:采用了多阶段的多任务混合训练,第一阶段为特征提取层,输入为N个点云点,通过PointNet++骨干网络通过FPS(最远点采样策略[5])等过程采样M个特征[6]并通过下采样和上采样实现编码器解码器架构提取M个候选点的环境语义特征;第二阶段接ApproachNet,即为视点(viewpoint,approaching vector。如图2中的v向量)候选生成;第三,在OperationNet和ToleranceNet之前有一个分组和对齐的功能(CloudCrop里进行的实现),这个功能和之前的二阶段目标检测的ROIPooling或ROIAlign的作用类似,对对照说明,第四:OperationNet的功能时对角度进行分类(通过离散化化细粒度的角度范围通过分类实现角度预测,每个角度下对应着一个夹爪宽度预测,因此为3通道,其中k为离散化的depth数目,如一个bin为0.01m,具体的实现参考OperationNet),ToleranceNet的作用为预测每一个抓取姿势的抗干扰能力,其真值的大体思路为在抓取姿势的邻域空间进行评估,如果其邻近抓取空间的抓取分数都大于一定的阈值,则其抗干扰能力相对就高。
References
- [1]、论文《GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping》参考网站: GraspNet通用物体抓取
- [2]、GraspNet-1Billion开源代码仓库地址:graspnet/graspnet-baseline: Baseline model for “GraspNet-1Billion
- [3]、关于GraspNet和RT-1模型的对比说明 · kindlytree-aics/graspnet-baseline Wiki
- [4]、数据收集和标注方法: 6D抓取学习(一)–深入解析GraspNet-1Billion数据集 – 知乎
- [5]、PointNet++模型中的最远点采样等实现: https://tinyurl.com/4dsjd3bt
- [6]、PointNet++实现思路: PointNet 实现特性 · kindlytree-aics/graspnet-baseline Wiki
Leave a Reply