这篇文章将向大家简要介绍DeepSeek-V1/V2/V3的模型结构及其发展演化过程。
在介绍DeepSeek的模型结构之前,这里简要复习一下LLM关键的基于Transformer架构图的模型结构的主要知识和技术点。
Transformer的基本架构,包括多头自注意力机制,FFN等关键组件。其中自注意力机制也分为双向的(Multi-Head Self Attention)以及causal的(Masked Multi-head Self Attention),一般双向自注意力模块的用于编码器结构(如BERT,基于WordPiece分词器),主要用于上下文丰富语义信息提取,为下游任务如文本分类等提供很好的文本特征提取功能;causal自注意模块用于解码器架构(如GPT,基于BPE分词器),主要用于文本生成(自回归语言生成,基于之前生成的内容来生成后续的内容,为基于单向时序因果的计算逻辑,通过掩码机制进行计算),如问答系统等的应用,两种模块都会用到的为编码器解码器组合结构(Auto Encoder,双向自注意力结构和caual+交叉自注意力模块),主要用于机器翻译,序列转换等应用任务。
DeepSeek的文本生成,数学推理,代码补全等任务上基于传统的Transformer的解码器架构框架,但在两个核心组件上进行了调整:1为MSA到MLA(Multi-head Latent Attention)的调整;2为FFN到MoE组件的调整。下面将一一进行简要介绍。
MLA组件和原始Transformer版本的MSA的结构类似,差异仅仅在于对于token embedding的输入维度进行了降维,将其映射到隐空间上进行表示。可以理解为将token的embedding维度进行了压缩后进行的自注意力机制的计算,在计算之后再通过提升维度达到和原始的token embedding的维度一致。而原始版本的MSA中K,Q,V矩阵的第二个维度会保持和token embedding的维度一致(可以理解为一种在token上进行了基于类似扩展的VAE的算法实现了计算性能上的优化)。
MoE(Mixture of Experts)的基本原理是使用混合专家来替代原transformer架构中的前向反馈层(FFN),MOE层由多个FFN组成,每个FFN理论上更关注不同领域知识,即领域专家,每个token会选择其中的top-K(top-K为模型超参)个FFN向前传递。在具体实现时由路由选择组件和前向FFN专家集合组成。
问题1:MoE可以理解为首先用类似于早期的注意力机制选择token embedding的重要信息从而实现降维,然后将所得结果输送给多个领域专家进行计算聚合,可以这么理解对吗?
回答: 这种理解不是很正确,TopKRouter实现动态路,其核心功能为选择部分的token给对应的专家网络模块实现领域专家的计算。具体点的实现思路为: 基于门控网络(简单线性层+Softmax)实现TopK进行稀疏选择,将token输入给前topk个专家进行领域计算(剩下的专家不参与token的计算),这样可以较大效率提升计算效率,同时实现了不同专家的隐式领域划分,采用了负载均衡损失保证专家之间的计算平衡。同时聚合是基于token的,如token的结果由两个专家来进行领域计算,则结果为两个专家计算结果的加权和(topk权重之和归一化到1)。
其中负载均衡损失函数的定义可以参考参考[2]中的说明,其中fi为理想的专家分配概率分布(均匀分布),pi为实际的第i个token对于每个专家的概率分布,loss的计算可以基于KL散度进行计算。负载均衡损失只是一个约束项,在均匀性和有效性之间找到平衡。负载均衡损失的目的是防止专家塌陷,而不是让选择完全随机。
DeepSeek-V1模型在MoE的设计上做了两处的改进,具体如下图所示:(1)、细粒度的专家模型分割,采用了更多的专家模型子模块;(2)、采用了共享专家模型,学习通用知识。
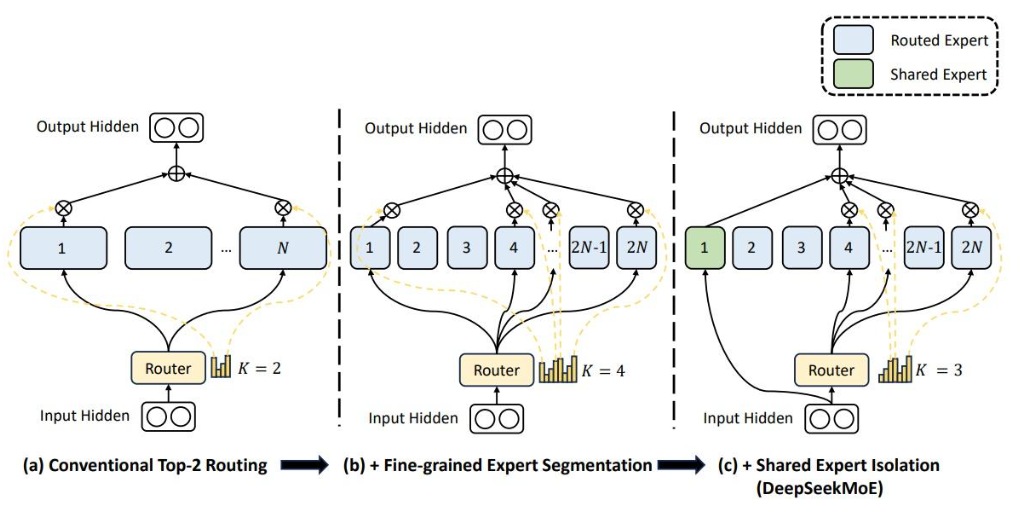
问题2:请分析一下switch transformer和deepseek v1/v2/v3中的moe的实现上的模型结构,负载均衡损失等上的设计差别?
回答:DeepSeek的MoE架构的介绍见参考引文[2]。其中由于MoE的数量较多(v2版本路由专家达到160个),通常也会采用专家并行的策略,将专家分配到多个GPU设备上进行并行计算,但由于如果同一个token分配到的GPU设备如果过多,就会存在着GPU之间的通信开销问题,因此也会在路由中加入了设备数量限制。以达到通信的负载较为均衡的目的。v2中有160个路由专家,6个激活专家,v3的路由专家有256个,8个激活专家。v3在负载均衡的损失设计上也做了较大调整,
References
- [1]、专家混合模型样例代码实现: 从零实现一个MOE(专家混合模型)
- [2]、负载均衡损失函数的解释: 万字解析DeepSeek MOE架构——从Switch Transformers到DeepSeek v1/v2/v3
- [3]、DeepSeek-MoE: deepseek-ai/DeepSeek-MoE: DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- [4]、知乎相关DeepSeek-MoE架构介绍:万字解析DeepSeek MOE架构——从Switch Transformers到DeepSeek v1/v2/v3
Leave a Reply