这篇文章将向大家介绍具身智能通用策略模型UniAct,其主要思想是对异构的具身智能机器人动作空间进行统一表示,然而显示的动作空间在不同的具身智能机器人上面差异较大,这里论文的作者提出了基于隐式的通用动作空间表示方法,认为这些隐式动作元语空间(latent action primitives)中的原子动作(图1中的atomic behaviors)可以通过加权组合成支持多种异构机器人的具体动作。
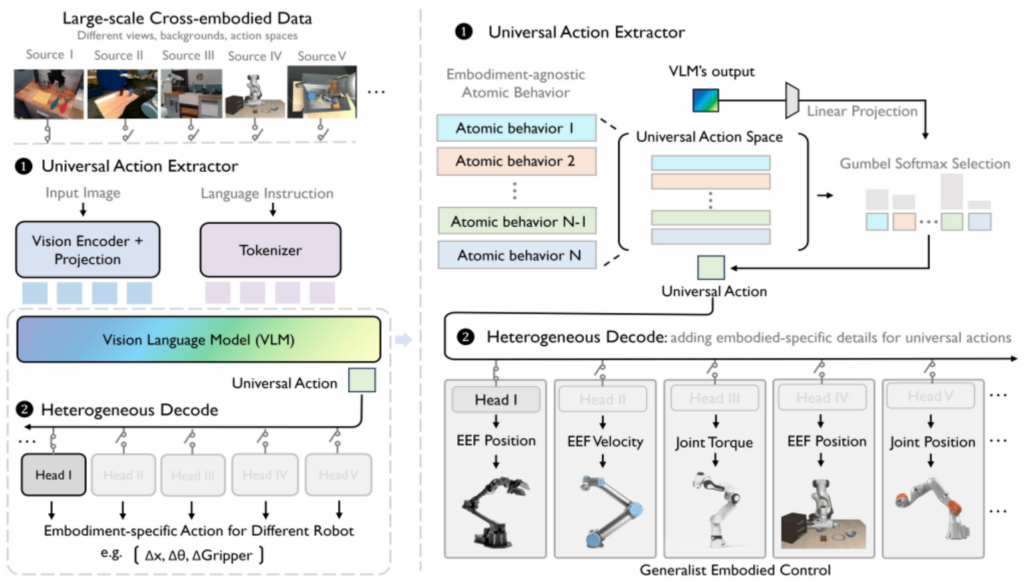
如图1中的右边部分所示,对于UniAct的结构的解释说明如下:1、多模态大模型Backbone:VLM模型为LlavaOnevisionForConditionalGeneration,支持视觉和自然语言的多模态信息融合(多个模态数据不是进行cross attention计算而是在输入层进行拼接融合);2、universal_actions_codebook为universal action语义信息融合提取层,在这里定义了码本codebook(离散表示空间,如codebook_size=64则表示64个动作元语组成动作元语空间),基于codebook_size=64个latent action primitives的加权和输出universal action embeddings,关于加权和的权重如何通过参数学习可以参考引文[2]中的问题2描述;3、action head,在代码实现中提供了两种head: (1)将universal action embeddings和vision_embedding(vision embedding通过专门的视觉嵌入信息提取模型计算获得)拼接作为三层MLP的输入输出特定的机器人action行为预测(MLP_Decoder);(2)在上面的基础上输入中再多加入本体感知观测数据proprios(ACT_Decoder),具体的描述参考引文[2]中的问题3描述。
论文中进行了较为全面的实验和评估,模型针对真实环境的机器人验证集和模拟环境的机器人数据验证集均做了评估(针对仿真数据做了finetune训练),以及将backbone和codebook的参数进行冻结,来适配新的任务head(如上所述的ACT_Decoder)的模型通用性扩展性验证实验及评估。实验结果说明了模型结构和实验过程的有效性。
References
- [1]、Universal Actions for Enhanced Embodied Foundation Models: 2501.10105
- [2]、UniAct 模型结构分析: UniAct_Model.md
Leave a Reply