在之前的关于马尔可夫决策过程的相关文章中,价值函数一般是某一状态下后续执行行为序列(特定策略)所获得的价值期望。价值函数可以是状态价值函数或动作价值函数,状态价值函数通常用V(s)来表示,而动作价值函数一般用Q(s,a)来表示,其含义为在特定状态下采取动作a来表示后续的价值期望。其表示更加灵活(因为只有状态的价值函数是针对特定策略的,而Q函数多了a这个维度表达能力就更强了),在许多强化学习算法中,特别是基于动作的方法(如Q-learning和Deep Q-Networks),Q函数是中心概念。
下面是Q-learning算法的基本思路解释:
- 初始化Q表格: 算法开始时,会初始化一个Q表格,其中包含状态-动作对的估计值。这个表格通常是一个二维数组,其中行代表状态,列代表动作。
- 选择动作: 智能体根据当前的策略和Q表格中的值选择一个动作。初始时可以使用随机策略(如ε-greedy策略),后续则根据Q表格中的值来选择动作。
- 执行动作并观察奖励和下一个状态: 智能体执行选择的动作,并观察环境返回的奖励以及智能体转移到的下一个状态。
- 更新Q值: 智能体使用观察到的奖励和下一个状态,以及Q-learning算法中的更新规则来更新Q表格中相应状态-动作对的值。
- 重复步骤2至4: 智能体在环境中不断地与环境交互,选择动作、执行动作、观察奖励和下一个状态,然后更新Q值,直到满足停止条件(如达到最大迭代次数或Q值收敛)。
Q-learning的Q值更新规则通常使用了贝尔曼方程的近似形式,即将当前状态的Q值更新为当前奖励加上未来最大Q值的折扣后的值。这样可以不断地迭代更新Q值,逐步逼近最优的Q函数,从而学习到最优的策略。Q-learning的算法流程伪代码如下图所示。

对上述公式的解释如下:

一般情况下,可以设置为LMS loss:其中error为下面的表达式。
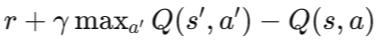
其中,在实际训练中,为了保持训练网络的稳定性,在训练过程中用到了两个网络,具体的过程可以参考引文3。
Q-learning的深度学习版本为DQN,原理基本差不多,不过Q函数不再以表格来表示,而是用神经网络的结构来表示,这样可以建模状态数很多的情况。
References
Leave a Reply