这篇文章向大家介绍VoxPoser算法的思路和创新方法。该论文提出了机器人应用中通过开放指令(通用任务)操作开放(通用)物体的一种技术实现方案,实现通过开放语言任务指令到密集的6自由度的终端执行器的任务轨迹合成,为未来日常通用任务机器人的实现提供一种技术思路和发展方向。总体思路和技术途径为:通过大语言模型在基于自由开放的任务指令上的任务理解和任务分解的优势,将自然语言指令转化为系统执行代码。
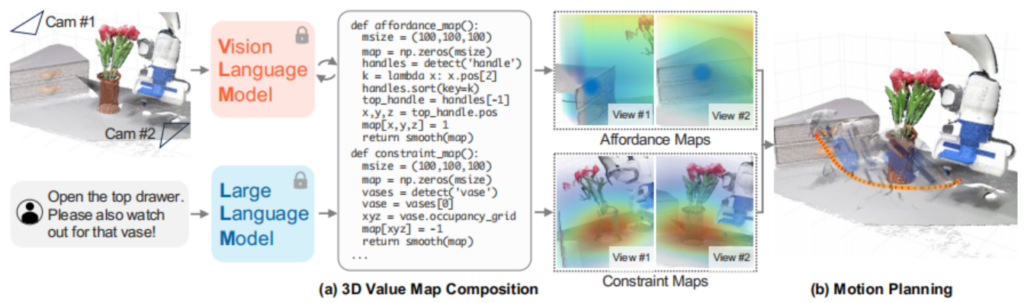
如图所示为VoxPoser算法流程示意图,一个完整的机器人任务从语言指令下达到路径点轨迹执行的整个过程主要由以下几个部分组成:1、基于代码生成微调后的大语言模型将开放语言指令进行子步骤分解,2、基于每一个步骤的子任务,基于感知模块(后面段落中有具体详细的说明)来构建多种类型的价值地图,过程1和2为如图1中的a部分;3、将各种价值图提供给路径规划算法,路径规划算法首先根据贪心算法找到局部最优的路径点序列,然后基于MPC相关算法来优化运动控制执行参数以驱动机器人执行相应动作,下面就相关过程做一下较为详细的说明。
首先,这篇文章基于LMPS的方法实现机器人通用任务,未来的理想机器人将不限于执行硬编码到系统中固定的操作任务,通过更前瞻的智能模型使得机器人通用操作任务功能成为可能。具体的LMP的原始想法来自于Code as Policies一文[1],这里对相关的多个层级的LMP的分工做一下简要说明(具体实例见引文[2]中的各个类别的LMP的Shots样例说明):1、planner,任务规划,将任务分解为多个子任务;2、composer,根据当前的子任务根据语言参数通过感知模块生成相应的value map LMPs(affordance, avoidance, gripper, rotation等等)。
论文中的感知模块部分pipeline过程较为复杂,包含几个步骤(但代码中并没有给出开源实现,也可以根据实际的物理和机器人部署软硬件环境对感知的pipeline进行自定义):1、基于开放词汇目标检测算法模型(Open-Vocab Detector)来检测特定物体,文中Open-Vocab Detector采用了google提出的OWL-ViT(Open-World Localization via Vision Transformer),该模型可以基于特定目标的语言描述,将图像和文本描述作为输入,输出目标物体的几何信息;2、然后将物体的boundingbox作为SAM(Segment Anything Model)模型的输入获取物体的mask;3、通过视觉跟踪算法对mask进行跟踪;4;跟踪的mask作为RGB-D图像的输入来获取目标物体或(物体的某个部分)的点云信息,在对较为稀疏的点云信息进行smooth插值后获得稠密的地图信息。
价值地图构建(Value Map Composition), 价值地图的结果以(100,100,100,k)形状的张量来表示体素值地图(vox value map),在可供性和约束性地图时k=1,表示cost代价值,在表示旋转地图时,k=4,表示旋转向量。
其次,动作规划(Motion Planner)基于可供性地图和约束性地图构成的价值地图采用贪婪搜索(greedy search)的方法来求解局部最优路径并进行平滑下采样等后处理,然后采用MPC相关算法优化执行参数并驱动硬件执行相关动作,在下一个执行时刻,会基于最新的观测数据重新调用动作规划以保证较高的实时准确性。
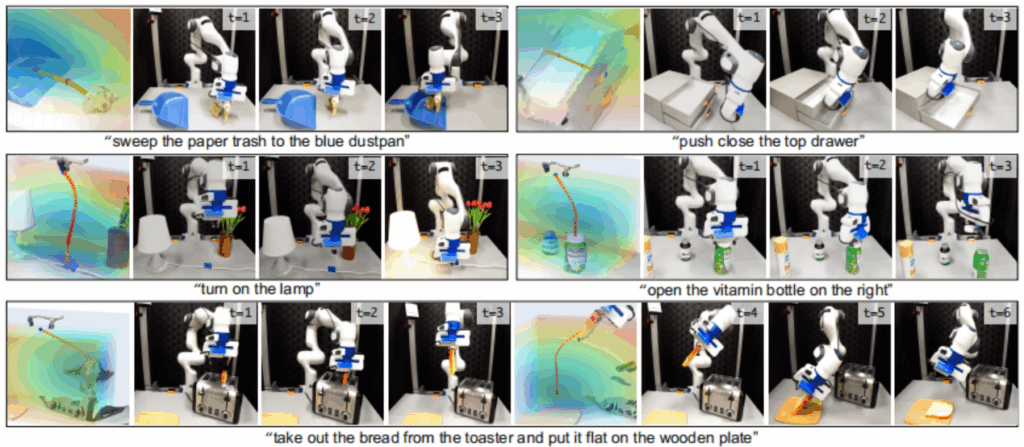
图2为相关任务场景和价值地图可视化示例,其中第一行中的“entity of interest”为objects(paper trash和 top drawer handler),可视化轨迹路径为黄色的path线条,下方两行的entity of interest为机械臂的夹爪,轨迹为红色的路径点连接而成的虚线条。
References
- [1]、Code as Polices: Code as Policies实现介绍
- [2]、各类LMP的few-shot prompt的上下文样例: prompts/rlbench
- [3]、VoxPoser相关解释: ./VoxPoser/paper_understanding.md
Leave a Reply