本篇文章将向大家介绍GRPO算法的基本原理,其也是DeepSeek模型训练所采用的关键算法。
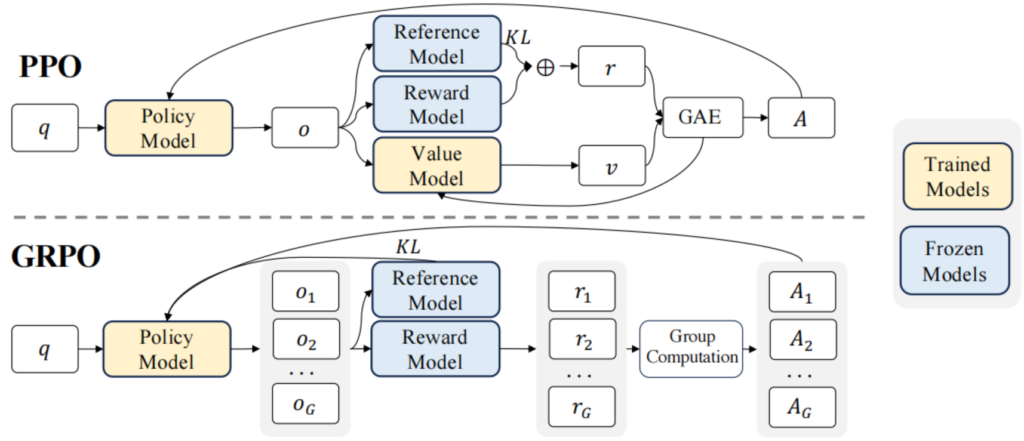
GRPO(Group Relative Policy Optimization)算法和PPO(近端策略优化算法)类似,其中相似的地方有基于优势函数和重要性采样机制以及梯度裁剪相结合的loss定义。但GRPO算法的创新的地方在于其优势函数的定义和计算方式不同,也是其优势所在。
PPO算法在rollout时基于一个prompt生成一个response(completion),而GRPO中会基于一个prompt生成多个completions,图1为两个算法的优势函数定义对比图。PPO算法的优势函数的公式中[1]有依赖于即时奖励和价值函数的计算,而GRPO算法中没有Value Model,从而省去了训练时Value Model的推理和梯度更新的计算资源。GRPO的优势函数的计算方式可以参考[2],其基于生成的多个completions分别用奖励模型去计算奖励,然后基于多个奖励值进行归一化(减去均值除以标准差)后得出优势函数的计算结果,这也是群体相对策略优化(Group Relative Policy Optimization)名称的由来。
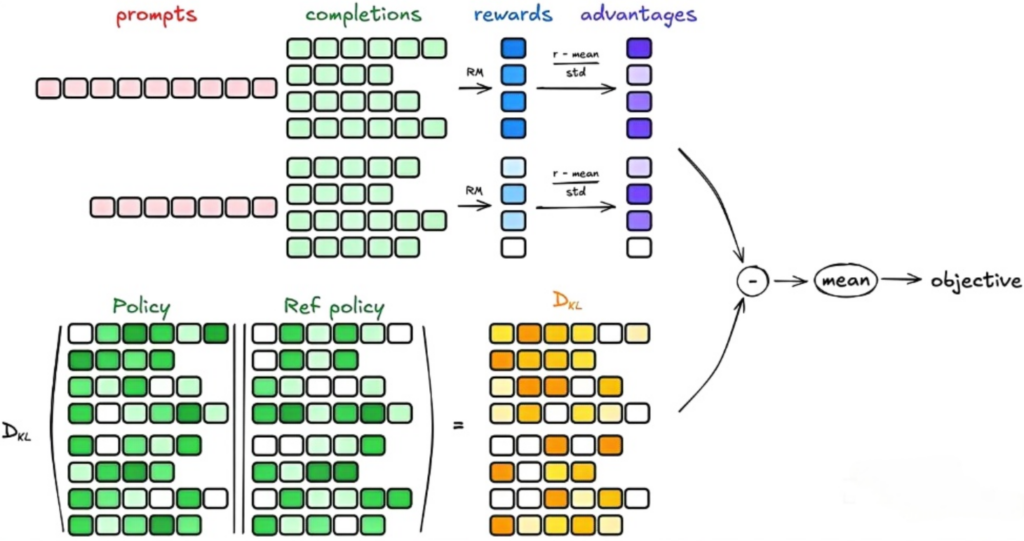
completions 之间的差异(diversity)正是由随机采样机制(如 top-k, top-p, temperature)来保证的,具体的这些超参在generation_config字典变量里进行设置。关于为什么用unwrapped model进行多个completions的生成以及采用model模型根据completion_ids进行logprobs的计算的原因可以参考相关issue[4]中的说明。
GPRO算法中的目标函数定义方法见图2。具体的计算时采用per_token_logps和ref_per_token_logps来计算训练模型的KL散度loss,同时用old_per_token_logps来计算模型当前rollout周期时生成completions样本时对应的per_token_logps(old_per_token_logps为当前数据采样周期时策略模型的生成的结果,可以达到一定程度的复用,用于策略模型的一个周期内的多次迭代;而ref_per_token_logps是参考模型的输出,用于计算KL loss,着PPO算法的机制相同)。详细的具体的实现参考代码[5]。
问题:ppo中critic和policy网络可以共享backbone,计算量也大不了多少?
回答:critic实现的价值网络虽然可以和policy网络共享backbone,但valuehead也需要在推理和梯度回传更新时需要不少资源。详细答案可以参考[3]中的描述。
问题:问答模型的数据集的格式是什么样的,如何实现不同推理场景的数据的统一描述?
回答:关于模型的训练数据方面的内容,如数据如何收集,数据的内容主题特性,以及如何通过角色实现对话上下文的管理并支持基于对话上下文的长token处理支持等内容,可以参考issue[6]中的描述。
References
- [1]、PPO算法的优势函数的定义和计算:TRL中PPO算法的优势函数定义 · Issue #IBRACZ
- [2]、DeepSeek的GRPO算法是什么? – 知乎
- [3]、grpo不依赖critic,但ppo中critic和policy网络可以共享backbone,计算量也大不了多少?
- [4]、为什么采用unwrapped model来计算多个completions,然后用model来计算logprobs,unwrapped在多样性生成方面和model相比有哪些优越性?
- [5]、TRL库中GRPO算法的实现: https://gitee.com/kindlytree/trl-with-comments/blob/main/trl/trainer/grpo_trainer.py#L709
- [6]、关于大语言模型数据集相关问题 · Issue #IBRSIC · kindlytree/TRL-with-comments
Leave a Reply