今天这篇文章向大家介绍Transformer网络架构在自然语言里边的基本应用,和以往的风格不同,今天的介绍以问答的形式展开,自己提出问题,自己给出解答,这样的形式也许也会引发读者在面对问题时先停下来尝试自己回答一下是否已经知晓答案,这样可能会触发更多的思考,从而会对问题有更加深入或全面的理解。
问题1:自然语言中的单词在网络的输入过程中以何种形式作为输入,以及这种表示方法的由来?怎么在输入中体现单词的位置信息?
回答:自然语言处理中,单词通过词嵌入向量进行表达(word embedding),词嵌入表达能够建模单词之间的语义信息,一般含义接近的单词其词向量之间的夹角更近,传统的词向量嵌入的方法有如Word2Vec、GloVe等(一般word embedding没有对向量进行归一化,但transformer中的LayerNorm层有归一化方法)。一般在word embedding的向量后面再拼接一个positional encoding来表示位置。具体的计算方法可以参考引文。参考引文5中(如Bert和GPT中用的词嵌入矩阵进行的转换,而且词嵌入矩阵在训练的起始可以随机初始化,然后训练过程作为整体参数的一部分参与训练更新参数学习词嵌入矩阵)。
问题2:针对K,Q,V的参数矩阵以及结果向量的计算方法是怎样的?
回答: 句子中的每个单词(word embedding+positional embedding)组成的矩阵和三个参数矩阵相乘后得出新的q,k,v三个矩阵,其中q和k的转置再实现矩阵相乘,得出单词之间的“相关性矩阵”(用softmax计算实现了相关性的大小的归一化计算?),将相关性矩阵和v矩阵相乘得出最后的结果z矩阵。如果是多头时,则会有多组参数矩阵,最终的多组z也会拼接起来并和一个新的参数矩阵相乘得出融合后的z‘。
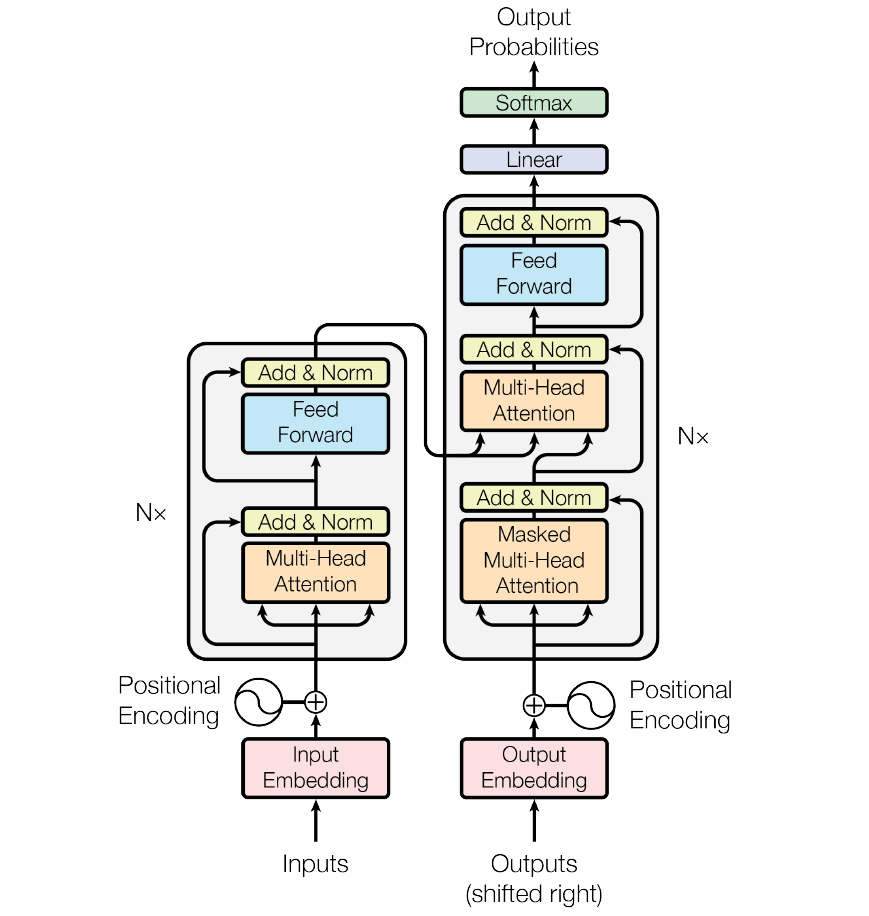
问题3:基于Transformer的encoder,decoder模型怎么进行训练?transformer的自编码器和seq2seq的模型的区别在哪里?
回答:首先基于transformer的自编码器和seq2seq的模型的应用目标不同,自编码器的应用目标是表示学习和语言重构,而seq2seq模型的目标是机器翻译,任务转换等。如下图所示,自编码器的模型结构包含左边的编码器部分,在训练的时候一般也要包含右边的解码器部分(右边解码模块每个解码层需要接收左边部分的K,V特征数据),只是在训练时可以理解为解码器的输出是对编码器的输入的重构。而seq2seq模型即包含编码器也包含解码器,而且在训练时输入和输出一般对应着不同的内容,如机器翻译,输入为一种语言,输出为另一种语言。这里以训练一句翻译的样本为例子进行说明,假设我们的输入句子是“Hello, how are you?”,目标翻译句子是“Bonjour, comment ça va ?”。则编码器的输入即为“Hello, how are you?”的词向量嵌入+位置编码组成的输入矩阵,而解码器的输入则为”<sos>Bonjour, comment ça”词向量嵌入+位置编码组成的输入矩阵,输出也会是向量的batch组成,输出的size为目标语言的词汇量,通过softmax可以得出最大可能的输出单词,多个批量向量就组成目标输出句子的output,和ground truth去求loss就能实现反向传播更新参数。具体的loss定义可以参看引文3(输出的序列的t从0到完整序列的多个条件概率连乘的结果最大化,具体的优化计算方法和策略也可以参考引文中的说明)。
References
Leave a Reply