在一般的电影和短视频中,一般的都存在的多个镜头(storyboard),为了保证镜头切换的时候的人物的一致性,需要文生图模型对此有较好的支持,否则在文生图的自动生成的场景中就会存在着不满足分镜头设计的需求,大模型的可用性就会受到交大影响。
今天向大家介绍midjourney中怎么实现人物一致性,主要通过一个实例向大家做演示介绍。
首先,我们通过提示词生成一个人物的不同角度的4张图片,提示词如下:
Chinese little boy, big eyes, black curly hair, red top, cyan pants, round face, slightly raised mouth, consistent character from multiple angles, face photos taken from multiple angles, front, sides with different orientations, four seperate images of the same person in produced big image --ar 1:1根据上述提示词生成的图片效果为:

将图像保存到本地,然后通过工具裁剪成4个小的图片,然后点击下图中左下脚的“+”号按钮在弹出的菜单中选择“上传文件”,将上面裁剪的4个图片上传后,将其链接保存下来(通过点击放大每个图片然后鼠标右键图片上方获取图片链接,供四个链接)。
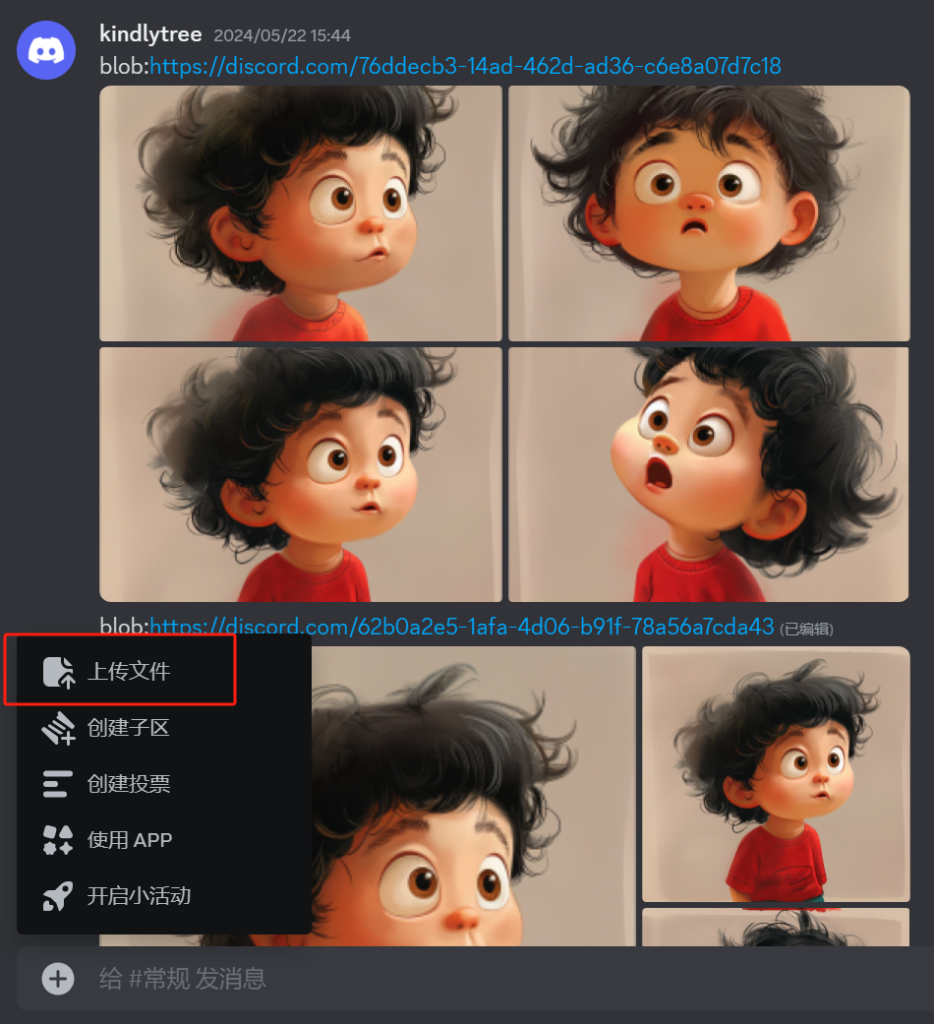
然后用/prefer option set命令来进行设置风格一致性,具体的指令形如下面截图:
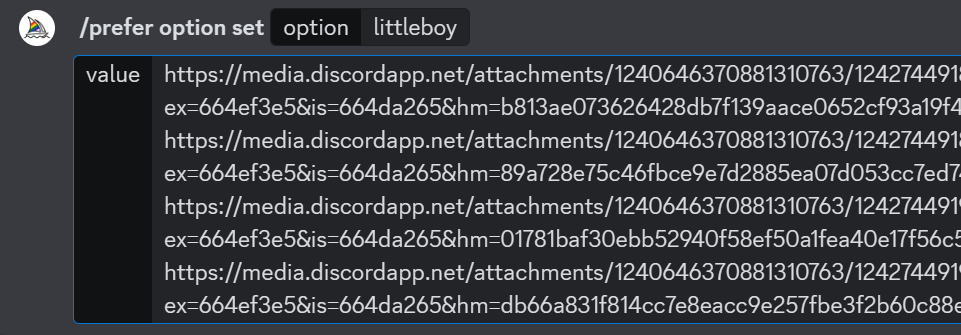
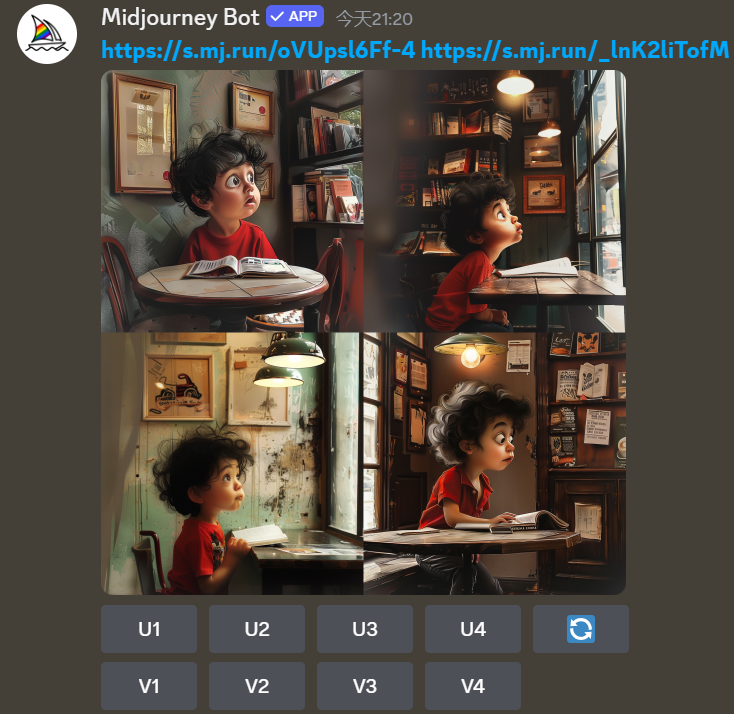
然后,就可以指定以该”littleboy”的option来生成人物一致性的场景了。具体的示例指令为:
/imagen --littleboy sitting besides the table in the coffee bar, read a book.最终的效果为:
后面有机会将继续向大家介绍关于图像视频多媒体方面的大模型应用的一些技巧。欢迎感兴趣的读者关注并提出问题一起来商议探讨共同提高。
Leave a Reply