前面的相关文章,介绍了基于价值函数的强化学习算法(MDP和Q-Learning),在强化学习中,除了基于值函数的方法,还有一支非常经典的方法,那就是基于策略(policy-based)的方法。这篇文章将向大家介绍相关的算法思想,不正确或需要修正的地方欢迎大家批评指正。
在前面介绍的Q-Learning算法中,会采用一定的随机策略去选择action(epsilon greedy),一开始会让Agent更偏向于探索Explore,并不是哪一个Action带来的Value最大就执行该Action,选择Action时具有一定的随机性,目的是为了覆盖更多的Action,尝试每一种可能性。等训练很多轮以后各种State下的各种Action基本尝试完以后,我们这时候会大幅降低探索的比例,尽量让Agent更偏向于利用Exploit,哪一个Action返回的Value最大,就选择哪一个Action。
在策略梯度中,Agent一般称为Actor,策略pi通常用一个神经网络来表示,一般神经网络的输出为动作的概率(如softmax)。智能体会自动的探索不同的状态和trajectory(通过随机采样的机制进行实现。如一个policy在某种状态下输出action1的概率为60%,输出action2的概率为40%,则智能体自然而然会更多采样到action1,但也会常采样到action2)。policy gradient还有”No more perceptual aliasing”和”Effective in high-dimensional action spaces“这样的优势,
从初始状态出发,到任务的结束,被称为一个完整的episode(剧集)。这样,一个有T个时刻的eposide,Actor不断与环境交互,形成如下的序列τ:
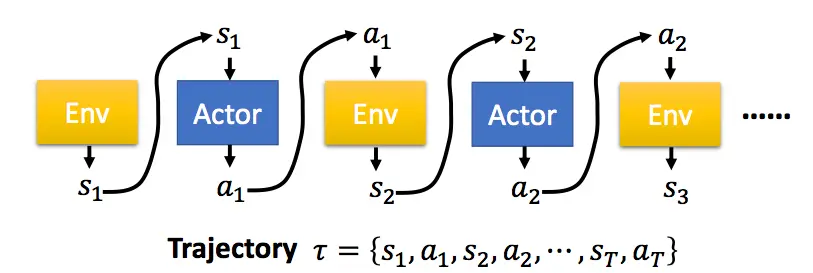
具体的公式推导可以参考引文1,最后的梯度求解公式如下:
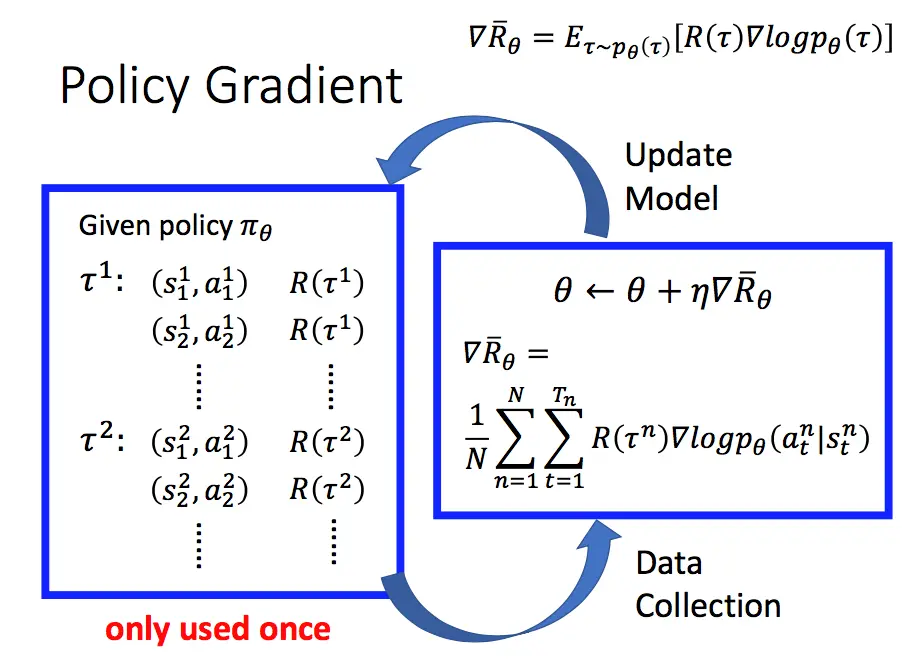
关于其公式的推导可以参考引文1,这里就不做赘述。需要说明和强调的是
对代码有几处说明一下:1、loss为负值,求最小,即为正值最大化,2,采用了Mento Carlo采样的思想,每次训练数据基于一个episode,从开始状态直至完成done;3、当前的某个时刻的R为从当前到最后状态r的一个折扣和,具体可以参考链接7中的实现。
实验中用到了GYM,强化学习算法工具包,可以提供强化学习算法的模拟环境,从而为测试和验证强化学习算法提供了方便。
References
- 1、Proximal Policy Optimization(PPO)算法原理及实现! – 简书 (jianshu.com)
- 2、PPO算法逐行代码详解 – 知乎 (zhihu.com)
- 3、策略梯度算法 (boyuai.com)
- 4、Policy Gradient Algorithms | Lil’Log (lilianweng.github.io)
- 5、[2401.13662] The Definitive Guide to Policy Gradients in Deep Reinforcement Learning: Theory, Algorithms and Implementations (arxiv.org)
- 6、Reinforcement Learning — Policy gradient 101 | by Mohamed Yosef | Medium
- 7、ai/samples/RL/PolicyGradient/policy.py at master · kindlytree/ai (github.com)
- 8、从头开始创建深度神经网络,介绍强化学习 第一部分:Gym环境和DNN架构 – 知乎 (zhihu.com)
- 9、引文7中的代码解释(蘑菇书RL,第80页): https://github.com/datawhalechina/easy-rl/releases/download/v1.0.6/EasyRL_v1.0.6.pdf
Leave a Reply