Apache hadoop项目开发了一个开源的可信赖,可伸缩的分布式计算软件,Hadoop是一个软件框架,采用简单的编程模型来在计算机集群上分布式的处理大量的数据,它被设计成可以从一台服务器伸缩到几千台机器,该开发框架可以在应用层检测和处理错误,从而在集群上能够提供高可用的服务。大数据的应用场景也有很多,大数据处理技术的集群环境可以用云计算平台搭建,大数据平台也可以作为云计算中的PaaS层提供给有大数据分析场景需求的用户使用。因此大数据技术一般也作为云计算技术专业的专业核心课程之一。后面有机会再和云平台结合具体详细介绍其搭建和使用。这里先做一下简要介绍。
Hadoop的核心组件包括:1、Hadoop Common,支持Hadoop其他模块的通用的一些工具库;2、HDFS(Hadoop Distributed File System)为应用程序提供高吞吐量的分布式文件系统;3、Hadoop YARN,为Hadoop系统中资源管理和任务调度(job scheduling)的框架;4、Hadoop MapReduce:是一个基于YARN系统的大数据集并行处理编程模型;5、Hadoop Ozone。本篇文章主要介绍一下其分布式文件系统的大体思想。
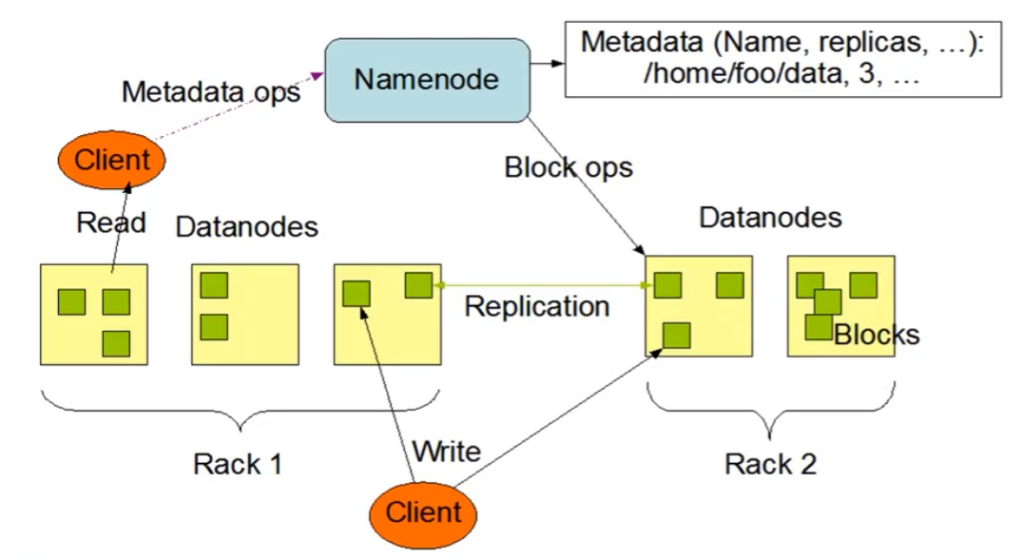
Hadoop HDFS(分布式文件系统),主节点进程(Namenode,存储元数据,文件的目录结构,不同节点之间的负载容量的计算),子节点(Datanode,多个,客户数据存储的地方),如图所示为一个客户端在上传文件时(下方的橙色的Client),将两个文件块上传到两个节点中去,然后文件块再创建对应的副本。HDFS和Ceph都属于大容量分布式存储,但是其实现思想方法和优缺点各有不同,怎么选择和结合使用要到后面有机会再详细介绍。
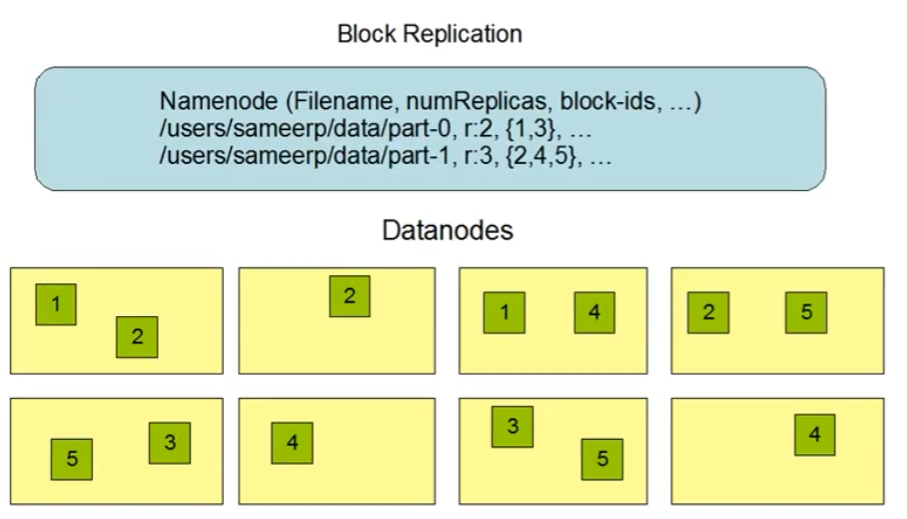
Hadoop中块副本(Block Replication)机制的如下图所示。为文件名,副本数量以及对应的块id号等信息。一般情况下默认副本数为3。
References
Leave a Reply