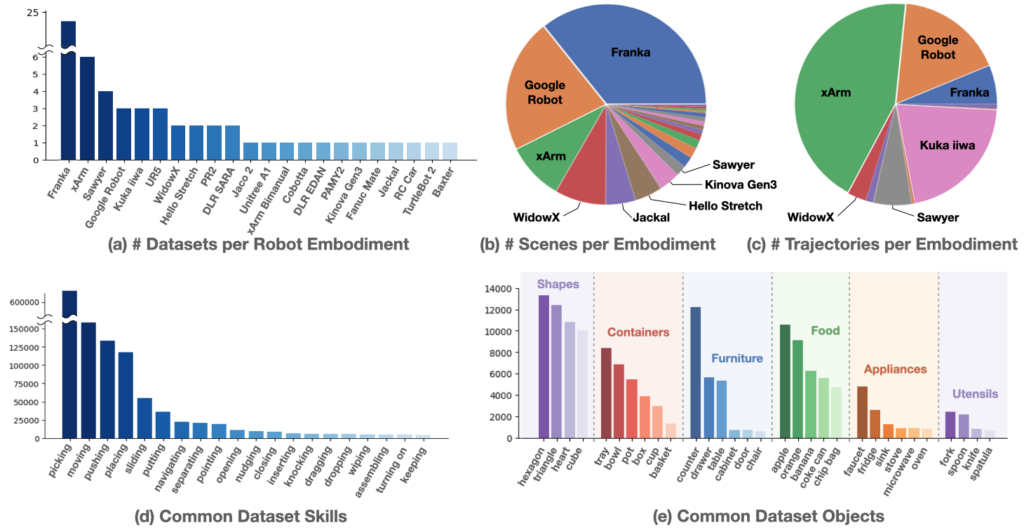
为了训练一个通用的机器人策略,Google推出了Open X-Embodiment数据集,通过在全球机器人实验室收集机械臂操作的数据集,历时大半年,一共得到了大大小小60多个来自21个组织结构34个机器人研究实验室的数据集,包含在22个机器人上采集的能够完成527种不同技能(skills)的16万个任务(160266 tasks)的上百万条数据。60个已有数据集中涉及到的机器人有单臂、双臂和四足,Franka占多数。下图为数据集的来源组织单位,可以看出诸多著名高校和研究结构都有参与其中。

可以看到除了这前面的一些动作有一定数量之外,其他的几百个动作的数量都非常少,技能数据呈现长尾分布(如下图中d所示)。
机器人大模型有两个典型代表,RT-1是高效的为机器人控制(robotic control)设计的基于transformer架构的模型,RT-2是一个大的视觉语言模型联合微调训练( co-fine-tuned)以输出机器人动作(以自然语言的表现形式,natural language tokens)。RT为Robotics Transformer的简称。RT1使用130k条机器人遥操作数据训练,展示出了其处理多种任务的能力和很强的泛化能力。但其通用性仍受限于数据集的大小。RT-1 的输入由图片序列、自然语言指令构成,输出由机械臂运动的目标位姿( Toll , pitch gaw , gripper stαtus)、基座的运动 、模式转换指令构成( The robot action is a 7-dimensional vector consisting of x, y, z, roll, pitch, yaw, and gripper opening or the rates of these quantities.)。RT-2抛弃了RT-1的设计,采用了利用网络上海量图文数据预训练出的图文模型,这些模型的规模可以最大达到55B的参数量,远远超过RT-1的35M的规模。这些图文模型被训练来回答关于图片的问题,原本的输出是文字,RT-2创造性的将机器人动作重新编码,使得编码为“文字”的机器人动作作为图文模型的输出。RT-X把提高扩展的目标放在了指令中的“动作”。
基于RT-1模型用该混合的机器人数据训练的结果模型为RT-1-X,基于RT-2模型用该混合的机器人数据训练的结果模型为RT-2-X,RT-1-X和RT-2-X比RT-1和RT-2模型性能优越了很多。得到的RT-1-X和RT-2-X模型表现出了很强的泛化能力和涌现能力(跨机器人实体学习的能力)。是以后更加通用智能的机器人的技术实现的曙光。
Open X-Embodiment数据集采用RLDS格式进行描述,RLDS为Reinforcement Learning Datasets的缩写,是一个用来存储,检索和操作序列的决策制订和执行的剧集数据(episodic data in the context of Sequential Decision Making),剧集一般记录一个完整的任务轨迹过程,比如一盘棋的下棋的步骤序列,在这里为机器人的一个任务的数据序列。如下图所示为一个episode数据的图像序列。如需了解数据集的更多的细节,可以参考引文中github里相关的代码链接。

行业内开源的好的数据集对于推动整个方向的发展起到了非常重要的作用,之前也有介绍过数据要素方面的博客短文(参考引文链接),具身机器人在将来将可以实现更多的任务,也可以在更多的应用场景中得到应用,数据集也可能会进一步扩充和丰富,以后如家务机器人,教育机器人等等也许会在不久后能够在实际生活中得到较好的应用。期待越来越多的算法和应用创新来丰富数字化场景的应用和数字化产业的发展,为社会经济提供新的增长动力,为人们的生活带来更多的便利和福祉。
References
- Open X-Embodiment: Robotic Learning Datasets and RT-X Models (robotics-transformer-x.github.io)
- Open X-Embodiment: Robotic Learning Datasets and RT-X Models 阅读笔记 – 知乎 (zhihu.com)
- RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control 阅读笔记 – 知乎 (zhihu.com)
- 谷歌推出全球最大通用大模型之一 RT-X,并开放训练数据集 – 腾讯云开发者社区-腾讯云 (tencent.com)
- 你真的了解Franka吗?一文带你揭秘Franka常见问题,你想知道的都在这里!(附产品手册)_BFT机器人的技术博客_51CTO博客
- 智元机器人彭志辉:具身智能即将为通用机器人补全最后一块拼图(深度好文) – 知乎 (zhihu.com)
- 机随语动,从RT-1到RT-2,再到RT-X – 知乎 (zhihu.com)
- GitHub – google-deepmind/open_x_embodiment
- 浅说数据要素 – 敬畏自然绿水青山 (kindlyrobot.cn)
Leave a Reply